Toggle navigation
主页
English
K8S
Golang
Guitar
About Me
归档
标签
Welcome to Sanger's Blog!
jaeger概述与helm安装
jaeger
2023-12-06 15:58:47
302
0
0
sanger
jaeger
[TOC] # jaeger概述 Jaeger 是一个分布式追踪平台,可用于监控和解决互连软件组件(称为微服务)上存在的问题。 多个微服务相互通信以完成单个软件功能。 开发人员使用 Jaeger 可视化这些微服务交互中的事件链,以便在出现问题时将其隔离。 Jaeger 也称为 Jaeger Tracing,因为它通过一系列微服务交互跟踪或追踪请求的路径。 IT 团队使用它来清晰了解整个事件链。他们可以更快地解决问题并改善客户体验。 ## Jaeger 的作用 开发人员使用 Jaeger 以几种不同的方式提高分布式系统的性能。 下面提供了一些示例。 ### 分布式事务监控 Jaeger 具有监控微服务之间的数据移动的功能。开发人员可以在中断用户体验之前采取积极主动的方法来检测和解决问题。 ### 延迟优化 Jaeger 分析可以定位微服务中降低应用程序速度的瓶颈。开发人员使用 Jaeger 来检查微服务的行为并寻找加快它们的方法。 ### 根本原因分析 在微服务架构中,一个问题可能会导致其他问题。开发人员可以使用 Jaeger 找到应用程序中一系列相关问题的起点。 ### 服务依赖性分析 服务依赖性意味着一个应用程序依赖于几个组件来运行。例如,导航应用程序依赖于移动应用程序上的定位服务。开发人员使用 Jaeger 来了解不同微服务之间的复杂关系。 ### 分布式上下文传播 分布式上下文传播是应用程序与数据一起传递描述性信息的方式。这有助于开发人员从整体上评估微服务性能。例如,Jaeger 使用客户姓名标记订单请求,以便开发人员可以将请求路径与特定客户相关联。 ## 架构图 https://www.jaegertracing.io/docs/1.23/architecture 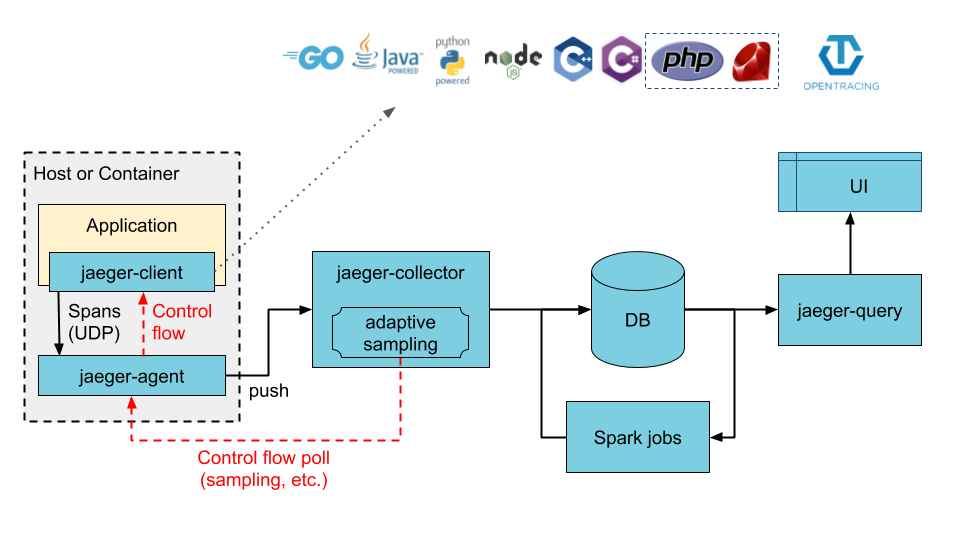 https://www.oreilly.com/library/view/kubernetes-for-developers/9781788834759/b331f4ea-21a3-4df4-b695-d31e240e5b15.xhtml 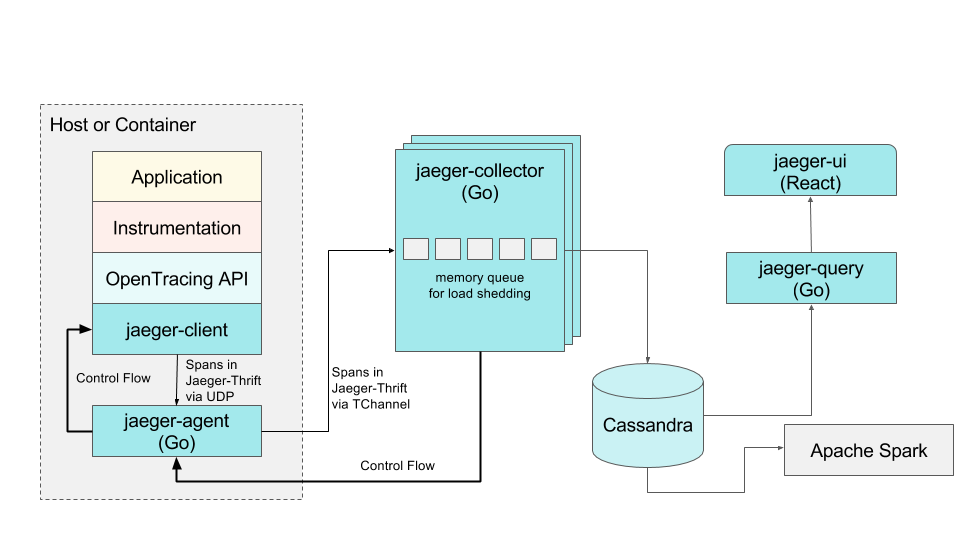 ## Jaeger组件 Jaeger 分布式追踪平台由以下组件组成 ### Jaeger client sdk Jaeger 客户端包含使用 Go、JavaScript、Java、Python、Ruby 和 PHP 等编程语言的 OpenTracing API 的特定语言实施。 开发人员使用这些 API 来创建 Jaeger 跨度,而无需编写用于分布式跟踪的源代码。 ### Jaeger agent Jaeger 代理是网络进程守护程序或在后台连续运行以执行其他进程所需功能的进程。它会侦听客户端通过用户数据报协议(UDP)发送的跨度,这是一种允许应用程序通过网络交换消息的通信方法。 代理连接到容器环境中的客户端。 代理组批量创建跨度并将它们发送到收集器。 这允许应用程序在不主动向 Jaeger 后端发送跟踪信息的情况下运行。 ### Jaeger collector Jaeger 收集器是从 Jaeger 收集器检索跟踪的软件组件。 它会检查、处理和存储数据库中的跟踪。 ### Storage Jaeger 跟踪系统接收span并将它们存储在持久存储后端或数据库中,持久存储是指即使计算机断电,存储的数据也会完好无损。 目前支持 Cassandra、Elasticsearch 和 Kafka 作为持久存储。 ### Jaeger Ingestor Ingester 是一项从 Kafka topic 读取并写入另一个存储后端(Cassandra、Elasticsearch)的服务。 ### Jaeger query Jaeger query是一项服务,用于从存储中检索 traces 并托管 UI 以显示它们。 开发人员使用查询来查找具有特定时间、标签、持续时间和操作的跟踪。 Jaeger UI是一个具有用户界面的软件程序,您可以使用它来查看和分析跟踪。 它以图形和图表的形式显示跟踪数据。 ## Jaeger 的工作原理 Jaeger 采用分布式跟踪的原则,并使用 OpenTracing 框架。 ### 分布式跟踪 分布式跟踪是一种监控微服务之间事件序列的软件技术。 它跟踪所有连接并提供图表以可视化应用程序中的请求路径。 作为一种分布式跟踪工具,Jaeger 通过为每个请求分配一个唯一标识符并在特定服务处理请求时收集信息来跟踪请求移动。 ### OpenTracing OpenTracing 是一个开源或免费提供的框架,它提供了在现代软件系统中实现准确、交钥匙分布式跟踪的标准。例如,它提供了一个通用标准,用于定义在微服务之间传输的受监控信息的结构。 Jaeger 使用 OpenTracing 提供完整的解决方案来收集、存储、管理、分析和可视化微服务数据。 ### OpenTracing 数据模型 OpenTracing 数据模型提供了连接来自不同组件的数据的基本定义。 它使用的两个主要术语是跨度和跟踪。 ### span(跨度) 跨度是在分布式跟踪系统中完成的单个逻辑工作单元。 每个跨度都包含以下组件: - 操作名称 - 开始时间和停止时间 - 帮助开发人员分析跨度的标签或值 - 存储微服务生成的任何消息的日志 - 跨度上下文或跨度的附加描述 ### trace(跟踪) 跟踪是属于同一进程的一个或多个跨度的集合。 它代表在特定时间发生的事件。 属于同一跟踪的跨度共享相同的跟踪 ID。 例如,当客户订购食物时生成的跟踪会产生以下跨度: - 客户提交订单 - 处理付款 - 订单清单被提交给餐厅 - 拣选食物 - 食物送达 # 环境和工具情况简述 环境:k8s集群版本 1.26.3 系统:aliyun os 2.x == centos 7.x jaeger版本:1.51 helm版本:3.13.2 # 整合opentelemetry-collector后整体的流程 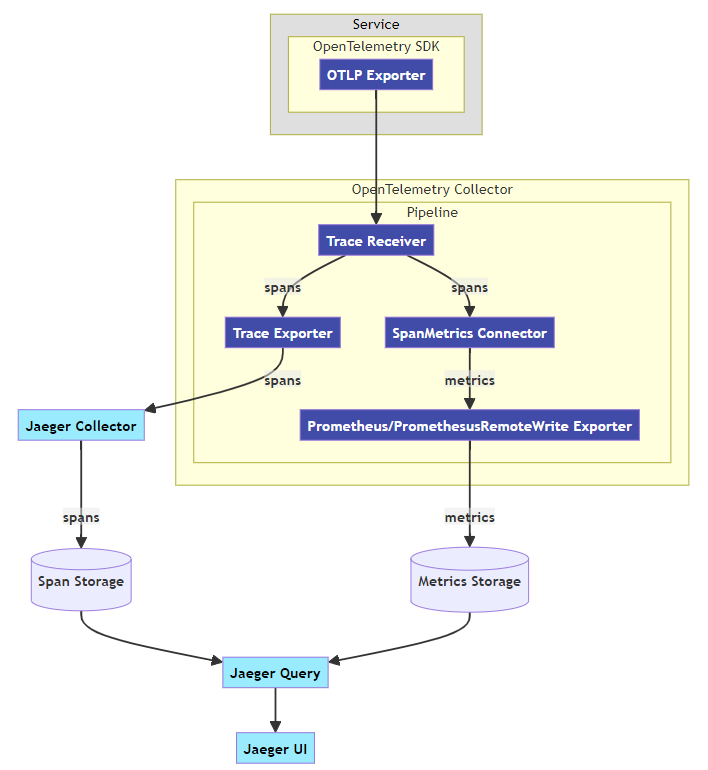 [opentelemetry-collector的安装请参考](https://docs.zh3.fun/blog/post/sanger/1ce8998e20ba) # 准备 ``` #安装jaeger官方库 helm repo add jaegertracing https://jaegertracing.github.io/helm-charts #helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts #helm repo add elastic https://helm.elastic.co #helm repo add aliyuncs https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts # 查看当前的jaeger版本 [dev-test@ops-deploy ops]$ helm search repo jaegertracing NAME CHART VERSION APP VERSION DESCRIPTION jaegertracing/jaeger 0.72.1 1.51.0 A Jaeger Helm chart for Kubernetes jaegertracing/jaeger-operator 2.49.0 1.49.0 jaeger-operator Helm chart for Kubernetes #如果觉得版本老的,可以更新下repo [dev-test@ops-deploy ops]$ helm repo update Hang tight while we grab the latest from your chart repositories... ...Successfully got an update from the "aliyuncs" chart repository ...Successfully got an update from the "open-telemetry" chart repository ...Successfully got an update from the "elastic" chart repository ...Successfully got an update from the "jaegertracing" chart repository Update Complete. ⎈Happy Helming!⎈ ``` ## jaeger values.yaml > 里面有些配置是自定义调试的,为了配置otel和prometheus等应用 比如SPM参考了官方文档:https://www.jaegertracing.io/docs/1.51/spm ``` # Default values for jaeger. # This is a YAML-formatted file. # Jaeger values are grouped by component. Cassandra values override subchart values provisionDataStore: cassandra: true elasticsearch: false kafka: false networkPolicy: enabled: false # Overrides the image tag where default is the chart appVersion. tag: "" nameOverride: "" fullnameOverride: "" allInOne: enabled: false replicas: 1 image: jaegertracing/all-in-one imagePullSecrets: [] pullPolicy: IfNotPresent extraEnv: [] extraSecretMounts: [] # - name: jaeger-tls # mountPath: /tls # subPath: "" # secretName: jaeger-tls # readOnly: true # command line arguments / CLI flags # See https://www.jaegertracing.io/docs/cli/ args: [] # samplingConfig: |- # { # "default_strategy": { # "type": "probabilistic", # "param": 1 # } # } service: headless: false collector: otlp: grpc: name: otlp http: name: otlp-http ingress: enabled: false # For Kubernetes >= 1.18 you should specify the ingress-controller via the field ingressClassName # See https://kubernetes.io/blog/2020/04/02/improvements-to-the-ingress-api-in-kubernetes-1.18/#specifying-the-class-of-an-ingress # ingressClassName: nginx annotations: {} labels: {} # Used to create an Ingress record. # hosts: # - chart-example.local # annotations: # kubernetes.io/ingress.class: nginx # kubernetes.io/tls-acme: "true" # labels: # app: jaeger # tls: # # Secrets must be manually created in the namespace. # - secretName: chart-example-tls # hosts: # - chart-example.local pathType: # resources: # limits: # cpu: 500m # memory: 512Mi # requests: # cpu: 256m # memory: 128Mi nodeSelector: {} storage: # allowed values (cassandra, elasticsearch) type: cassandra cassandra: host: cassandra port: 9042 # Change this value to false if you want to avoid starting the # -cassandra-schema Job schemaJobEnabled: true tls: enabled: false secretName: cassandra-tls-secret user: user usePassword: true password: password keyspace: jaeger_v1_test ## Use existing secret (ignores previous password) # existingSecret: ## Cassandra related env vars to be configured on the concerned components extraEnv: [] # - name: CASSANDRA_SERVERS # value: cassandra # - name: CASSANDRA_PORT # value: "9042" # - name: CASSANDRA_KEYSPACE # value: jaeger_v1_test # - name: CASSANDRA_TLS_ENABLED # value: "false" ## Cassandra related cmd line opts to be configured on the concerned components cmdlineParams: {} # cassandra.servers: cassandra # cassandra.port: 9042 # cassandra.keyspace: jaeger_v1_test # cassandra.tls.enabled: "false" elasticsearch: scheme: http host: elasticsearch-master port: 9200 anonymous: false user: elastic usePassword: true password: changeme # indexPrefix: test ## Use existing secret (ignores previous password) # existingSecret: # existingSecretKey: nodesWanOnly: false extraEnv: [] ## ES related env vars to be configured on the concerned components # - name: ES_SERVER_URLS # value: http://elasticsearch-master:9200 # - name: ES_USERNAME # value: elastic # - name: ES_INDEX_PREFIX # value: test ## ES related cmd line opts to be configured on the concerned components cmdlineParams: {} # es.server-urls: http://elasticsearch-master:9200 # es.username: elastic # es.index-prefix: test tls: enabled: false secretName: es-tls-secret # The mount properties of the secret mountPath: /es-tls/ca-cert.pem subPath: ca-cert.pem # How ES_TLS_CA variable will be set in the various components ca: /es-tls/ca-cert.pem kafka: brokers: - kafka:9092 topic: jaeger_v1_test authentication: none extraEnv: [] grpcPlugin: extraEnv: [] # Begin: Override values on the Cassandra subchart to customize for Jaeger cassandra: persistence: # To enable persistence, please see the documentation for the Cassandra chart enabled: true config: cluster_name: jaeger seed_size: 1 dc_name: dc1 rack_name: rack1 endpoint_snitch: GossipingPropertyFileSnitch # End: Override values on the Cassandra subchart to customize for Jaeger # Begin: Override values on the Kafka subchart to customize for Jaeger kafka: replicaCount: 1 autoCreateTopicsEnable: true zookeeper: replicaCount: 1 serviceAccount: create: true # End: Override values on the Kafka subchart to customize for Jaeger # Begin: Default values for the various components of Jaeger # This chart has been based on the Kubernetes integration found in the following repo: # https://github.com/jaegertracing/jaeger-kubernetes/blob/main/production/jaeger-production-template.yml # # This is the jaeger-cassandra-schema Job which sets up the Cassandra schema for # use by Jaeger schema: annotations: {} image: jaegertracing/jaeger-cassandra-schema imagePullSecrets: [] pullPolicy: IfNotPresent #resources: # {} resources: limits: cpu: 500m memory: 512Mi # requests: # cpu: 256m # memory: 128Mi serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: true name: podAnnotations: {} podLabels: {} securityContext: {} podSecurityContext: {} ## Deadline for cassandra schema creation job activeDeadlineSeconds: 300 extraEnv: - name: TRACE_TTL value: "604800" # - name: CASSANDRA_DATA_DIRECTORY # value: "/data" #[] # - name: MODE # value: prod # - name: DEPENDENCIES_TTL # value: "0" # For configurable values of the elasticsearch if provisioned, please see: # https://github.com/elastic/helm-charts/tree/master/elasticsearch#configuration elasticsearch: {} ingester: enabled: false podSecurityContext: {} securityContext: {} annotations: {} image: jaegertracing/jaeger-ingester imagePullSecrets: [] pullPolicy: IfNotPresent dnsPolicy: ClusterFirst cmdlineParams: {} replicaCount: 1 autoscaling: enabled: false minReplicas: 2 maxReplicas: 10 behavior: {} # targetCPUUtilizationPercentage: 80 # targetMemoryUtilizationPercentage: 80 service: annotations: {} # List of IP ranges that are allowed to access the load balancer (if supported) loadBalancerSourceRanges: [] type: ClusterIP resources: {} # limits: # cpu: 1 # memory: 1Gi # requests: # cpu: 500m # memory: 512Mi serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: false name: nodeSelector: {} tolerations: [] affinity: {} podAnnotations: {} ## Additional pod labels ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ podLabels: {} extraSecretMounts: [] extraConfigmapMounts: [] extraEnv: [] envFrom: [] serviceMonitor: enabled: false additionalLabels: {} # https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/api.md#relabelconfig relabelings: [] # -- ServiceMonitor metric relabel configs to apply to samples before ingestion # https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#endpoint metricRelabelings: [] agent: podSecurityContext: {} securityContext: {} enabled: true annotations: {} image: jaegertracing/jaeger-agent # tag: 1.22 imagePullSecrets: [] pullPolicy: IfNotPresent cmdlineParams: {} extraEnv: [] daemonset: useHostPort: false updateStrategy: {} # type: RollingUpdate # rollingUpdate: # maxUnavailable: 1 service: annotations: {} # List of IP ranges that are allowed to access the load balancer (if supported) loadBalancerSourceRanges: [] type: ClusterIP # zipkinThriftPort :accept zipkin.thrift over compact thrift protocol zipkinThriftPort: 5775 # compactPort: accept jaeger.thrift over compact thrift protocol compactPort: 6831 # binaryPort: accept jaeger.thrift over binary thrift protocol binaryPort: 6832 # samplingPort: (HTTP) serve configs, sampling strategies samplingPort: 5778 resources: limits: cpu: 500m memory: 512Mi # requests: # cpu: 256m # memory: 128Mi #{} serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: false name: annotations: {} nodeSelector: {} tolerations: [] affinity: {} podAnnotations: {} ## Additional pod labels ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ podLabels: {} extraSecretMounts: [] # - name: jaeger-tls # mountPath: /tls # subPath: "" # secretName: jaeger-tls # readOnly: true extraConfigmapMounts: [] # - name: jaeger-config # mountPath: /config # subPath: "" # configMap: jaeger-config # readOnly: true envFrom: [] useHostNetwork: false dnsPolicy: ClusterFirst priorityClassName: "" initContainers: [] serviceMonitor: enabled: false additionalLabels: {} # https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/api.md#relabelconfig relabelings: [] # -- ServiceMonitor metric relabel configs to apply to samples before ingestion # https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#endpoint metricRelabelings: [] collector: podSecurityContext: {} securityContext: {} enabled: true annotations: {} image: jaegertracing/jaeger-collector # tag: 1.22 imagePullSecrets: [] pullPolicy: IfNotPresent dnsPolicy: ClusterFirst extraEnv: [] envFrom: [] cmdlineParams: {} basePath: / replicaCount: 1 autoscaling: enabled: false minReplicas: 2 maxReplicas: 10 behavior: {} # targetCPUUtilizationPercentage: 80 # targetMemoryUtilizationPercentage: 80 service: annotations: {} # The IP to be used by the load balancer (if supported) loadBalancerIP: "" # List of IP ranges that are allowed to access the load balancer (if supported) loadBalancerSourceRanges: [] type: ClusterIP # Cluster IP address to assign to service. Set to None to make service headless clusterIP: "" grpc: port: 14250 # nodePort: # httpPort: can accept spans directly from clients in jaeger.thrift format http: port: 14268 # nodePort: # can accept Zipkin spans in JSON or Thrift zipkin: # {} port: 9411 # nodePort: otlp: grpc: # {} name: otlp port: 4317 # nodePort: http: # {} name: otlp-http port: 4318 # nodePort: ingress: enabled: false # For Kubernetes >= 1.18 you should specify the ingress-controller via the field ingressClassName # See https://kubernetes.io/blog/2020/04/02/improvements-to-the-ingress-api-in-kubernetes-1.18/#specifying-the-class-of-an-ingress # ingressClassName: nginx annotations: {} labels: {} # Used to create an Ingress record. # The 'hosts' variable accepts two formats: # hosts: # - chart-example.local # or: # hosts: # - host: chart-example.local # servicePort: grpc # annotations: # kubernetes.io/ingress.class: nginx # kubernetes.io/tls-acme: "true" # labels: # app: jaeger-collector # tls: # Secrets must be manually created in the namespace. # - secretName: chart-example-tls # hosts: # - chart-example.local pathType: resources: limits: cpu: 1 memory: 1Gi # requests: # cpu: 500m # memory: 512Mi #{} serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: false name: annotations: {} nodeSelector: {} tolerations: [] affinity: {} podAnnotations: {} ## Additional pod labels ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ podLabels: {} extraSecretMounts: [] # - name: jaeger-tls # mountPath: /tls # subPath: "" # secretName: jaeger-tls # readOnly: true extraConfigmapMounts: [] # - name: jaeger-config # mountPath: /config # subPath: "" # configMap: jaeger-config # readOnly: true # samplingConfig: |- # { # "service_strategies": [ # { # "service": "foo", # "type": "probabilistic", # "param": 0.8, # "operation_strategies": [ # { # "operation": "op1", # "type": "probabilistic", # "param": 0.2 # }, # { # "operation": "op2", # "type": "probabilistic", # "param": 0.4 # } # ] # }, # { # "service": "bar", # "type": "ratelimiting", # "param": 5 # } # ], # "default_strategy": { # "type": "probabilistic", # "param": 1 # } # } priorityClassName: "" serviceMonitor: enabled: false additionalLabels: {} # https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/api.md#relabelconfig relabelings: [] # -- ServiceMonitor metric relabel configs to apply to samples before ingestion # https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#endpoint metricRelabelings: [] initContainers: [] networkPolicy: enabled: false # ingressRules: # namespaceSelector: {} # podSelector: {} # customRules: [] # egressRules: # namespaceSelector: {} # podSelector: {} # customRules: [] query: enabled: true basePath: / oAuthSidecar: enabled: false resources: {} # limits: # cpu: 500m # memory: 512Mi # requests: # cpu: 256m # memory: 128Mi image: quay.io/oauth2-proxy/oauth2-proxy:v7.1.0 pullPolicy: IfNotPresent containerPort: 4180 args: [] extraEnv: [] extraConfigmapMounts: [] extraSecretMounts: [] # config: |- # provider = "oidc" # https_address = ":4180" # upstreams = ["http://localhost:16686"] # redirect_url = "https://jaeger-svc-domain/oauth2/callback" # client_id = "jaeger-query" # oidc_issuer_url = "https://keycloak-svc-domain/auth/realms/Default" # cookie_secure = "true" # email_domains = "*" # oidc_groups_claim = "groups" # user_id_claim = "preferred_username" # skip_provider_button = "true" podSecurityContext: {} securityContext: {} agentSidecar: enabled: true resources: limits: cpu: 500m memory: 512Mi # requests: # cpu: 256m # memory: 128Mi annotations: {} image: jaegertracing/jaeger-query # tag: 1.22 imagePullSecrets: [] pullPolicy: IfNotPresent dnsPolicy: ClusterFirst #cmdlineParams: {} #extraEnv: [] extraEnv: - name: METRICS_STORAGE_TYPE value: "prometheus" - name: PROMETHEUS_SERVER_URL value: "http://prometheus-k8s.monitoring.svc.cluster.local:9090" # - name: PROMETHEUS_QUERY_NORMALIZE_CALLS # value: "true" # - name: PROMETHEUS_QUERY_NORMALIZE_DURATION # value: "true" envFrom: [] replicaCount: 1 service: annotations: {} type: ClusterIP # List of IP ranges that are allowed to access the load balancer (if supported) loadBalancerSourceRanges: [] port: 80 # Specify a custom target port (e.g. port of auth proxy) # targetPort: 8080 # Specify a specific node port when type is NodePort # nodePort: 32500 ingress: enabled: enable # For Kubernetes >= 1.18 you should specify the ingress-controller via the field ingressClassName # See https://kubernetes.io/blog/2020/04/02/improvements-to-the-ingress-api-in-kubernetes-1.18/#specifying-the-class-of-an-ingress ingressClassName: proxy annotations: {} labels: {} # Used to create an Ingress record. hosts: - jaeger-.xxx.com # annotations: # kubernetes.io/ingress.class: nginx # kubernetes.io/tls-acme: "true" # labels: # app: jaeger-query # tls: # Secrets must be manually created in the namespace. # - secretName: chart-example-tls # hosts: # - chart-example.local pathType: health: exposed: false resources: limits: cpu: 500m memory: 512Mi # requests: # cpu: 256m # memory: 128Mi #{} serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: false name: annotations: {} nodeSelector: {} tolerations: [] affinity: {} podAnnotations: {} ## Additional pod labels ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ podLabels: {} extraConfigmapMounts: [] # - name: jaeger-config # mountPath: /config # subPath: "" # configMap: jaeger-config # readOnly: true extraVolumes: [] sidecars: [] ## - name: your-image-name ## image: your-image ## ports: ## - name: portname ## containerPort: 1234 priorityClassName: "" serviceMonitor: enabled: true additionalLabels: {} # https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/api.md#relabelconfig relabelings: [] # -- ServiceMonitor metric relabel configs to apply to samples before ingestion # https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/api.md#endpoint metricRelabelings: [] # config: |- # { # "dependencies": { # "dagMaxNumServices": 200, # "menuEnabled": true # }, # "archiveEnabled": true, # "tracking": { # "gaID": "UA-000000-2", # "trackErrors": true # } # } networkPolicy: enabled: false # ingressRules: # namespaceSelector: {} # podSelector: {} # customRules: [] # egressRules: # namespaceSelector: {} # podSelector: {} # customRules: [] spark: enabled: true annotations: {} image: jaegertracing/spark-dependencies imagePullSecrets: [] tag: latest pullPolicy: IfNotPresent cmdlineParams: {} extraEnv: [] schedule: "0 0 * * *" successfulJobsHistoryLimit: 5 failedJobsHistoryLimit: 5 concurrencyPolicy: Forbid resources: limits: cpu: 1 memory: 4Gi #{} # limits: # cpu: 500m # memory: 512Mi # requests: # cpu: 256m # memory: 128Mi serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: false name: nodeSelector: {} tolerations: [] affinity: {} extraSecretMounts: [] extraConfigmapMounts: [] podAnnotations: {} ## Additional pod labels ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ podLabels: {} # ttlSecondsAfterFinished: 120 esIndexCleaner: enabled: false securityContext: runAsUser: 1000 podSecurityContext: runAsUser: 1000 annotations: {} image: jaegertracing/jaeger-es-index-cleaner imagePullSecrets: [] pullPolicy: IfNotPresent cmdlineParams: {} extraEnv: [] # - name: ROLLOVER # value: 'true' schedule: "55 23 * * *" successfulJobsHistoryLimit: 3 failedJobsHistoryLimit: 3 concurrencyPolicy: Forbid resources: {} # limits: # cpu: 500m # memory: 512Mi # requests: # cpu: 256m # memory: 128Mi numberOfDays: 7 serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: false name: nodeSelector: {} tolerations: [] affinity: {} extraSecretMounts: [] extraConfigmapMounts: [] podAnnotations: {} ## Additional pod labels ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ podLabels: {} # ttlSecondsAfterFinished: 120 esRollover: enabled: false securityContext: {} podSecurityContext: runAsUser: 1000 annotations: {} image: jaegertracing/jaeger-es-rollover imagePullSecrets: [] tag: latest pullPolicy: IfNotPresent cmdlineParams: {} extraEnv: - name: CONDITIONS value: '{"max_age": "1d"}' schedule: "10 0 * * *" successfulJobsHistoryLimit: 3 failedJobsHistoryLimit: 3 concurrencyPolicy: Forbid resources: {} # limits: # cpu: 500m # memory: 512Mi # requests: # cpu: 256m # memory: 128Mi serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: false name: nodeSelector: {} tolerations: [] affinity: {} extraSecretMounts: [] extraConfigmapMounts: [] podAnnotations: {} ## Additional pod labels ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ podLabels: {} # ttlSecondsAfterFinished: 120 initHook: extraEnv: [] # - name: SHARDS # value: "3" annotations: {} podAnnotations: {} podLabels: {} ttlSecondsAfterFinished: 120 esLookback: enabled: false securityContext: {} podSecurityContext: runAsUser: 1000 annotations: {} image: jaegertracing/jaeger-es-rollover imagePullSecrets: [] tag: latest pullPolicy: IfNotPresent cmdlineParams: {} extraEnv: - name: UNIT value: days - name: UNIT_COUNT value: "7" schedule: "5 0 * * *" successfulJobsHistoryLimit: 3 failedJobsHistoryLimit: 3 concurrencyPolicy: Forbid resources: {} # limits: # cpu: 500m # memory: 512Mi # requests: # cpu: 256m # memory: 128Mi serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: false name: nodeSelector: {} tolerations: [] affinity: {} extraSecretMounts: [] extraConfigmapMounts: [] podAnnotations: {} ## Additional pod labels ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ podLabels: {} # ttlSecondsAfterFinished: 120 # End: Default values for the various components of Jaeger hotrod: enabled: false podSecurityContext: {} securityContext: {} replicaCount: 1 # set the primary command(s) for the hotrod application args: - all # add extra arguments to the hotrod application to customize tracing extraArgs: [] # - --otel-exporter=otlp # - --jaeger-ui=http://jaeger.chart.local # add extra environment variables to the hotrod application extraEnv: [] # - name: OTEL_EXPORTER_OTLP_ENDPOINT # value: http://my-otel-collector.chart.local:4318 image: repository: jaegertracing/example-hotrod pullPolicy: IfNotPresent pullSecrets: [] service: annotations: {} name: hotrod type: ClusterIP # List of IP ranges that are allowed to access the load balancer (if supported) loadBalancerSourceRanges: [] port: 80 ingress: enabled: false # For Kubernetes >= 1.18 you should specify the ingress-controller via the field ingressClassName # See https://kubernetes.io/blog/2020/04/02/improvements-to-the-ingress-api-in-kubernetes-1.18/#specifying-the-class-of-an-ingress # ingressClassName: nginx # Used to create Ingress record (should be used with service.type: ClusterIP). hosts: - chart-example.local annotations: {} # kubernetes.io/ingress.class: nginx # kubernetes.io/tls-acme: "true" tls: # Secrets must be manually created in the namespace. # - secretName: chart-example-tls # hosts: # - chart-example.local pathType: resources: {} # We usually recommend not to specify default resources and to leave this as a conscious # choice for the user. This also increases chances charts run on environments with little # resources, such as Minikube. If you do want to specify resources, uncomment the following # lines, adjust them as necessary, and remove the curly braces after 'resources:'. # limits: # cpu: 100m # memory: 128Mi # requests: # cpu: 100m # memory: 128Mi serviceAccount: create: true # Explicitly mounts the API credentials for the Service Account automountServiceAccountToken: false name: nodeSelector: {} tolerations: [] affinity: {} tracing: host: null port: 6831 # Array with extra yaml objects to install alongside the chart. Values are evaluated as a template. extraObjects: [] ``` ## cassandra values.yaml ``` ## Cassandra image version ## ref: https://hub.docker.com/r/library/cassandra/ image: repo: cassandra tag: 3.11.6 pullPolicy: IfNotPresent ## Specify ImagePullSecrets for Pods ## ref: https://kubernetes.io/docs/concepts/containers/images/#specifying-imagepullsecrets-on-a-pod # pullSecrets: myregistrykey ## Specify a service type ## ref: http://kubernetes.io/docs/user-guide/services/ service: type: ClusterIP annotations: "" ## Use an alternate scheduler, e.g. "stork". ## ref: https://kubernetes.io/docs/tasks/administer-cluster/configure-multiple-schedulers/ ## # schedulerName: ## Persist data to a persistent volume persistence: enabled: true ## cassandra data Persistent Volume Storage Class ## If defined, storageClassName: <storageClass> ## If set to "-", storageClassName: "", which disables dynamic provisioning ## If undefined (the default) or set to null, no storageClassName spec is ## set, choosing the default provisioner. (gp2 on AWS, standard on ## GKE, AWS & OpenStack) ## storageClass: "jaeger-cassandra-hostpath" accessMode: ReadWriteOnce size: 100Gi ## Configure resource requests and limits ## ref: http://kubernetes.io/docs/user-guide/compute-resources/ ## Minimum memory for development is 4GB and 2 CPU cores ## Minimum memory for production is 8GB and 4 CPU cores ## ref: http://docs.datastax.com/en/archived/cassandra/2.0/cassandra/architecture/architecturePlanningHardware_c.html #resources: {} # requests: # memory: 4Gi # cpu: 2 # limits: # memory: 4Gi # cpu: 2 resources: requests: memory: 0 cpu: 0 limits: memory: 4Gi cpu: 2 ## Change cassandra configuration parameters below: ## ref: http://docs.datastax.com/en/cassandra/3.0/cassandra/configuration/configCassandra_yaml.html ## Recommended max heap size is 1/2 of system memory ## Recommended heap new size is 1/4 of max heap size ## ref: http://docs.datastax.com/en/cassandra/3.0/cassandra/operations/opsTuneJVM.html config: cluster_domain: cluster.local cluster_name: cassandra cluster_size: 1 seed_size: 2 num_tokens: 256 # If you want Cassandra to use this datacenter and rack name, # you need to set endpoint_snitch to GossipingPropertyFileSnitch. # Otherwise, these values are ignored and datacenter1 and rack1 # are used. dc_name: DC1 rack_name: RAC1 endpoint_snitch: SimpleSnitch max_heap_size: 2048M heap_new_size: 512M start_rpc: false ports: cql: 9042 thrift: 9160 # If a JVM Agent is in place # agent: 61621 ## Cassandra config files overrides configOverrides: {} #configOverrides: # cassandra.yaml: | # data_file_directories: # - /data ## Cassandra docker command overrides commandOverrides: [] ## Cassandra docker args overrides argsOverrides: [] ## Custom env variables. ## ref: https://hub.docker.com/_/cassandra/ env: {} ## Liveness and Readiness probe values. ## ref: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/ livenessProbe: initialDelaySeconds: 90 periodSeconds: 30 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 3 readinessProbe: initialDelaySeconds: 90 periodSeconds: 30 timeoutSeconds: 5 successThreshold: 1 failureThreshold: 3 address: "${POD_IP}" ## Configure node selector. Edit code below for adding selector to pods ## ref: https://kubernetes.io/docs/user-guide/node-selection/ selector: nodeSelector: kubernetes.io/role: prom # cloud.google.com/gke-nodepool: pool-db ## Additional pod annotations ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/annotations/ podAnnotations: {} ## Additional pod labels ## ref: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/ podLabels: {} ## Additional pod-level settings podSettings: # Change this to give pods more time to properly leave the cluster when not using persistent storage. terminationGracePeriodSeconds: 30 ## Pod distruption budget podDisruptionBudget: {} # maxUnavailable: 1 # minAvailable: 2 podManagementPolicy: OrderedReady updateStrategy: type: OnDelete ## Pod Security Context securityContext: enabled: false fsGroup: 999 runAsUser: 999 ## Affinity for pod assignment ## Ref: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/#affinity-and-anti-affinity affinity: {} ## Node tolerations for pod assignment ## Ref: https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/ tolerations: [] rbac: # Specifies whether RBAC resources should be created create: true serviceAccount: # Specifies whether a ServiceAccount should be created create: true # The name of the ServiceAccount to use. # If not set and create is true, a name is generated using the fullname template # name: # Use host network for Cassandra pods # You must pass seed list into config.seeds property if set to true hostNetwork: false ## Backup cronjob configuration ## Ref: https://github.com/maorfr/cain backup: enabled: false # Schedule to run jobs. Must be in cron time format # Ref: https://crontab.guru/ schedule: - keyspace: keyspace1 cron: "0 7 * * *" - keyspace: keyspace2 cron: "30 7 * * *" annotations: # Example for authorization to AWS S3 using kube2iam # Can also be done using environment variables iam.amazonaws.com/role: cain image: repository: maorfr/cain tag: 0.6.0 # Additional arguments for cain # Ref: https://github.com/maorfr/cain#usage extraArgs: [] # Add additional environment variables env: # Example environment variable required for AWS credentials chain - name: AWS_REGION value: us-east-1 resources: requests: memory: 1Gi cpu: 1 limits: memory: 1Gi cpu: 1 # Name of the secret containing the credentials of the service account used by GOOGLE_APPLICATION_CREDENTIALS, as a credentials.json file # google: # serviceAccountSecret: # Destination to store the backup artifacts # Supported cloud storage services: AWS S3, Minio S3, Azure Blob Storage, Google Cloud Storage # Additional support can added. Visit this repository for details # Ref: https://github.com/maorfr/skbn destination: s3://bucket/cassandra ## Cassandra exported configuration ## ref: https://github.com/criteo/cassandra_exporter exporter: enabled: false serviceMonitor: enabled: false additionalLabels: {} # prometheus: default image: repo: criteord/cassandra_exporter tag: 2.0.2 port: 5556 jvmOpts: "" resources: {} # limits: # cpu: 1 # memory: 1Gi # requests: # cpu: 1 # memory: 1Gi #extraVolumes: [] #extraVolumeMounts: [] #extraVolumes: # - name: cassandra-hostpath # hostPath: # path: /data/cassandra # type: DirectoryOrCreate #extraVolumeMounts: # - name: cassandra-hostpath # mountPath: /data # extraVolumes and extraVolumeMounts allows you to mount other volumes # Example Use Case: mount ssl certificates # extraVolumes: # - name: cas-certs # secret: # defaultMode: 420 # secretName: cas-certs # extraVolumeMounts: # - name: cas-certs # mountPath: /certs # readOnly: true extraContainers: [] ## Additional containers to be added # extraContainers: # - name: cassandra-sidecar # image: cassandra-sidecar:latest # volumeMounts: # - name: some-mount # mountPath: /some/path ``` ## cassadra持久化 > 使用本地卷pv和sc动态生成pvc绑定pod和pv实现持久化 ```jaeger-cassandra.yaml --- apiVersion: v1 kind: PersistentVolume metadata: name: jaeger-cassandra-pv labels: type: local spec: storageClassName: jaeger-cassandra-hostpath capacity: storage: 100Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain hostPath: path: "/data/cassandra" #--- #apiVersion: v1 #kind: PersistentVolumeClaim #metadata: # name: jaeger-cassandra-pvc #spec: # accessModes: # - ReadWriteOnce # resources: # requests: # storage: 50Gi --- apiVersion: storage.k8s.io/v1 allowVolumeExpansion: true #开启允许扩容功能,但是nfs类型不支持 kind: StorageClass metadata: name: jaeger-cassandra-hostpath #mountOptions: #- proto=tcp #- vers=4 #- minorversion=0 #- noresvport reclaimPolicy: Retain provisioner: xxx.com/hostpath #parameters: # archiveOnDelete: "false" ``` # 安装 ``` #安装 helm install jaeger -n tracing ./jaeger #更新 helm upgrade jaeger -n tracing ./jaeger #删除 helm uninstall jaeger -n tracing ``` # jaeger存储 >jaeger支持内存,cassandra、elasticsearsh、kafka作为后端存储 ## cassandra > 通过helm安装jaeger默认用的是cassandra作为后端存储,因为相对简单,而且天然支持数据生命周期. 通过 **default_time_to_live** 来控制数据的生命周期,value的单位为秒 通过 **gc_grace_seconds** 来控制数据的最终从磁盘上删除的时间,value的单位为秒 jaeger cassandra cql模板可以参考这里: https://github.com/jaegertracing/jaeger/blob/main/plugin/storage/cassandra/schema/v001.cql.tmpl ``` cqlsh:jaeger_v1_test> DESCRIBE jaeger_v1_test CREATE KEYSPACE jaeger_v1_test WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = true; CREATE TYPE jaeger_v1_test.dependency ( parent text, child text, call_count bigint, source text ); CREATE TYPE jaeger_v1_test.keyvalue ( key text, value_type text, value_string text, value_bool boolean, value_long bigint, value_double double, value_binary blob ); CREATE TYPE jaeger_v1_test.log ( ts bigint, fields list<frozen<keyvalue>> ); CREATE TYPE jaeger_v1_test.process ( service_name text, tags list<frozen<keyvalue>> ); CREATE TYPE jaeger_v1_test.span_ref ( ref_type text, trace_id blob, span_id bigint ); CREATE TABLE jaeger_v1_test.service_name_index ( service_name text, bucket int, start_time bigint, trace_id blob, PRIMARY KEY ((service_name, bucket), start_time) ) WITH CLUSTERING ORDER BY (start_time DESC) AND bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy', 'compaction_window_size': '1', 'compaction_window_unit': 'HOURS', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.0 AND default_time_to_live = 604800 AND gc_grace_seconds = 10800 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = 'NONE'; CREATE TABLE jaeger_v1_test.traces ( trace_id blob, span_id bigint, span_hash bigint, duration bigint, flags int, logs list<frozen<log>>, operation_name text, parent_id bigint, process frozen<process>, refs list<frozen<span_ref>>, start_time bigint, tags list<frozen<keyvalue>>, PRIMARY KEY (trace_id, span_id, span_hash) ) WITH CLUSTERING ORDER BY (span_id ASC, span_hash ASC) AND bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy', 'compaction_window_size': '1', 'compaction_window_unit': 'HOURS', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.0 AND default_time_to_live = 604800 AND gc_grace_seconds = 10800 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = 'NONE'; CREATE TABLE jaeger_v1_test.dependencies_v2 ( ts_bucket timestamp, ts timestamp, dependencies list<frozen<dependency>>, PRIMARY KEY (ts_bucket, ts) ) WITH CLUSTERING ORDER BY (ts DESC) AND bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.1 AND default_time_to_live = 0 AND gc_grace_seconds = 864000 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = '99PERCENTILE'; CREATE TABLE jaeger_v1_test.service_names ( service_name text PRIMARY KEY ) WITH bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.0 AND default_time_to_live = 604800 AND gc_grace_seconds = 10800 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = 'NONE'; CREATE TABLE jaeger_v1_test.service_operation_index ( service_name text, operation_name text, start_time bigint, trace_id blob, PRIMARY KEY ((service_name, operation_name), start_time) ) WITH CLUSTERING ORDER BY (start_time DESC) AND bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy', 'compaction_window_size': '1', 'compaction_window_unit': 'HOURS', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.0 AND default_time_to_live = 604800 AND gc_grace_seconds = 10800 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = 'NONE'; CREATE TABLE jaeger_v1_test.tag_index ( service_name text, tag_key text, tag_value text, start_time bigint, trace_id blob, span_id bigint, PRIMARY KEY ((service_name, tag_key, tag_value), start_time, trace_id, span_id) ) WITH CLUSTERING ORDER BY (start_time DESC, trace_id ASC, span_id ASC) AND bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy', 'compaction_window_size': '1', 'compaction_window_unit': 'HOURS', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.0 AND default_time_to_live = 604800 AND gc_grace_seconds = 10800 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = 'NONE'; CREATE TABLE jaeger_v1_test.sampling_probabilities ( bucket int, ts timeuuid, hostname text, probabilities text, PRIMARY KEY (bucket, ts) ) WITH CLUSTERING ORDER BY (ts DESC) AND bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.1 AND default_time_to_live = 0 AND gc_grace_seconds = 864000 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = '99PERCENTILE'; CREATE TABLE jaeger_v1_test.duration_index ( service_name text, operation_name text, bucket timestamp, duration bigint, start_time bigint, trace_id blob, PRIMARY KEY ((service_name, operation_name, bucket), duration, start_time, trace_id) ) WITH CLUSTERING ORDER BY (duration DESC, start_time DESC, trace_id ASC) AND bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.TimeWindowCompactionStrategy', 'compaction_window_size': '1', 'compaction_window_unit': 'HOURS', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.0 AND default_time_to_live = 604800 AND gc_grace_seconds = 10800 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = 'NONE'; CREATE TABLE jaeger_v1_test.leases ( name text PRIMARY KEY, owner text ) WITH bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.1 AND default_time_to_live = 0 AND gc_grace_seconds = 864000 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = '99PERCENTILE'; CREATE TABLE jaeger_v1_test.operation_throughput ( bucket int, ts timeuuid, throughput text, PRIMARY KEY (bucket, ts) ) WITH CLUSTERING ORDER BY (ts DESC) AND bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.1 AND default_time_to_live = 0 AND gc_grace_seconds = 864000 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = '99PERCENTILE'; CREATE TABLE jaeger_v1_test.operation_names_v2 ( service_name text, span_kind text, operation_name text, PRIMARY KEY (service_name, span_kind, operation_name) ) WITH CLUSTERING ORDER BY (span_kind ASC, operation_name ASC) AND bloom_filter_fp_chance = 0.01 AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'} AND comment = '' AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'} AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'} AND crc_check_chance = 1.0 AND dclocal_read_repair_chance = 0.0 AND default_time_to_live = 604800 AND gc_grace_seconds = 10800 AND max_index_interval = 2048 AND memtable_flush_period_in_ms = 0 AND min_index_interval = 128 AND read_repair_chance = 0.0 AND speculative_retry = 'NONE'; ``` ## elasticsearch > 以索引的方式存储数据,每天会新建二个带时间后缀的索引,如下所示: 可以通过定期删除es索引的方式来控制jaeger数据的生命周期 ``` [root@sanger-s ~]# curl http://es.xxx.com:9200/_cat/indices?v | sort -n % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 6050 100 6050 0 0 28139 0 --:--:-- --:--:-- --:--:-- 28139 health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open jaeger-service-2023-11-27 mppkr531QRuzYGq72UKsZg 5 1 54 18 129kb 129kb yellow open jaeger-service-2023-11-28 E4_iLlvfTdeiBZZFaMtR4g 5 1 98 16 100.5kb 100.5kb yellow open jaeger-service-2023-11-29 1rc7VPvWT5mlgobP9AhM9w 5 1 49 15 107.5kb 107.5kb yellow open jaeger-service-2023-11-30 Qgil9qnsSiO0SUjeRoWPbw 5 1 88 7 64.5kb 64.5kb yellow open jaeger-service-2023-12-01 kg2tflHxRO2jKSGZeYHpOg 5 1 28 2 92.7kb 92.7kb yellow open jaeger-span-2023-11-27 PuBxE5yEQTiXVcTxXwnKBA 5 1 300598 0 14.2mb 14.2mb yellow open jaeger-span-2023-11-28 7vDvWqMFQx2wkCHNr817uw 5 1 243464 0 12.7mb 12.7mb yellow open jaeger-span-2023-11-29 MWe4iiBaTLiayaXghhp0aw 5 1 186854 0 9.5mb 9.5mb yellow open jaeger-span-2023-11-30 rI6pYxPES9qyrIO-kqqwrQ 5 1 201406 0 10.3mb 10.3mb yellow open jaeger-span-2023-12-01 c_KsMEJ9RyCgFqS3Lo9nNw 5 1 28920 0 1.7mb 1.7mb ``` ## kafka 指定endpoint和topic将数据存储到kafka,可作为一个数据中转,不太适合长期的存储 # 最终展示 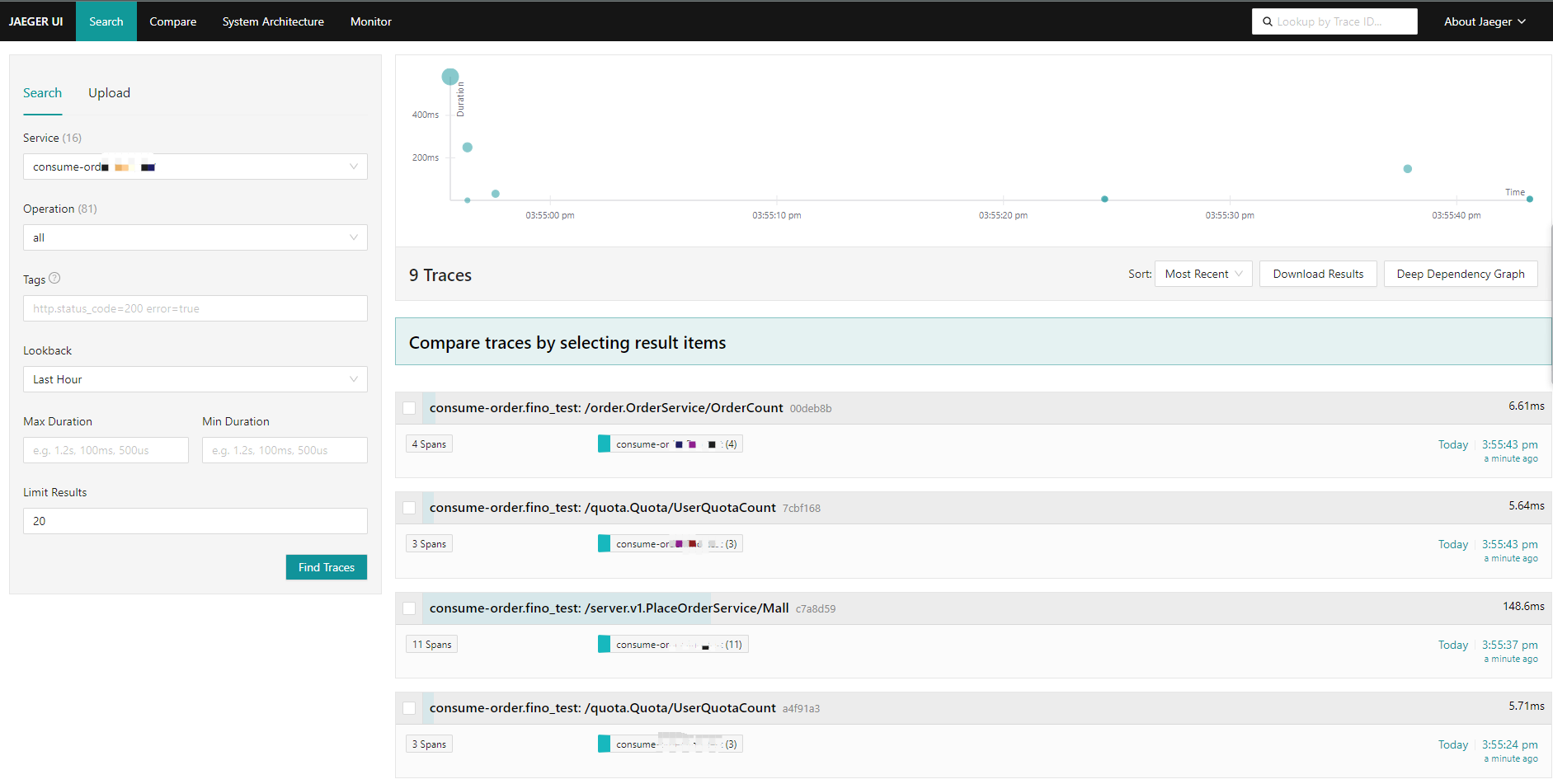 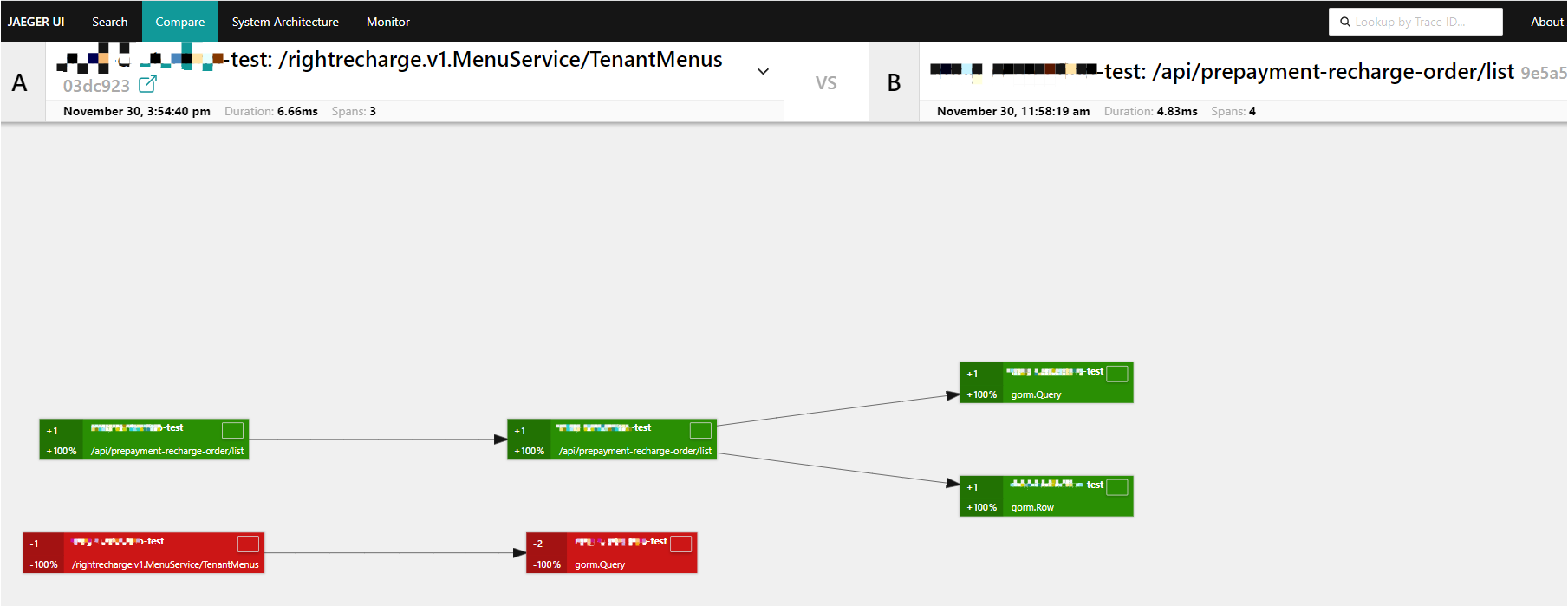 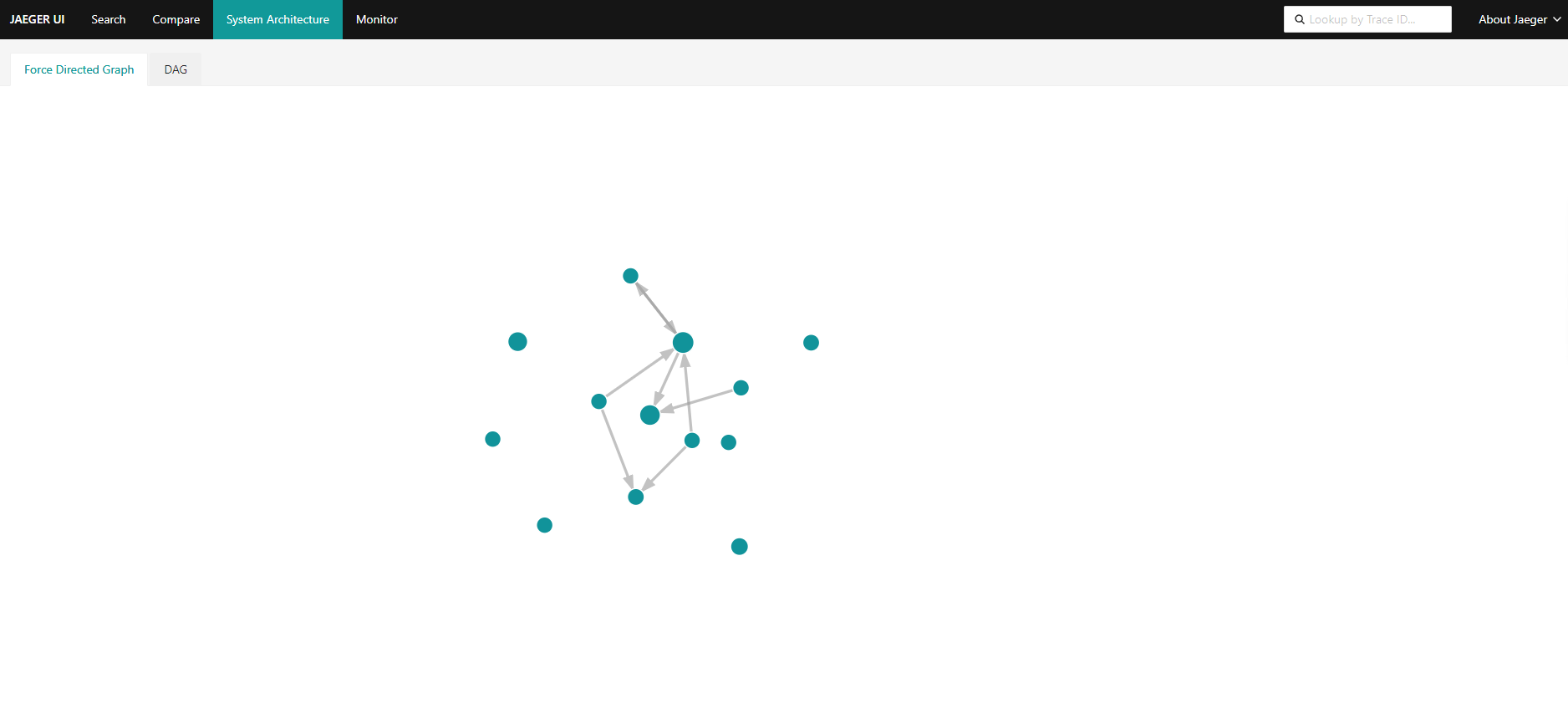 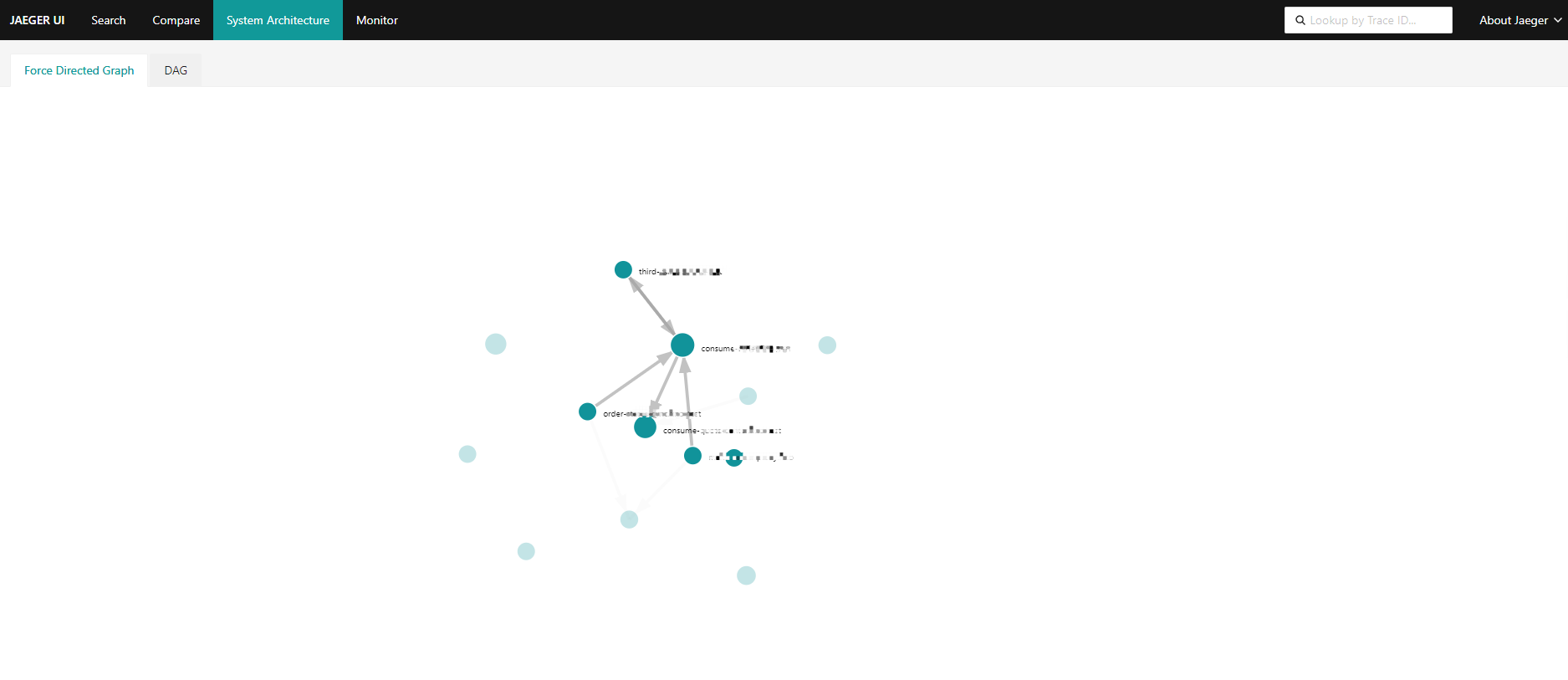 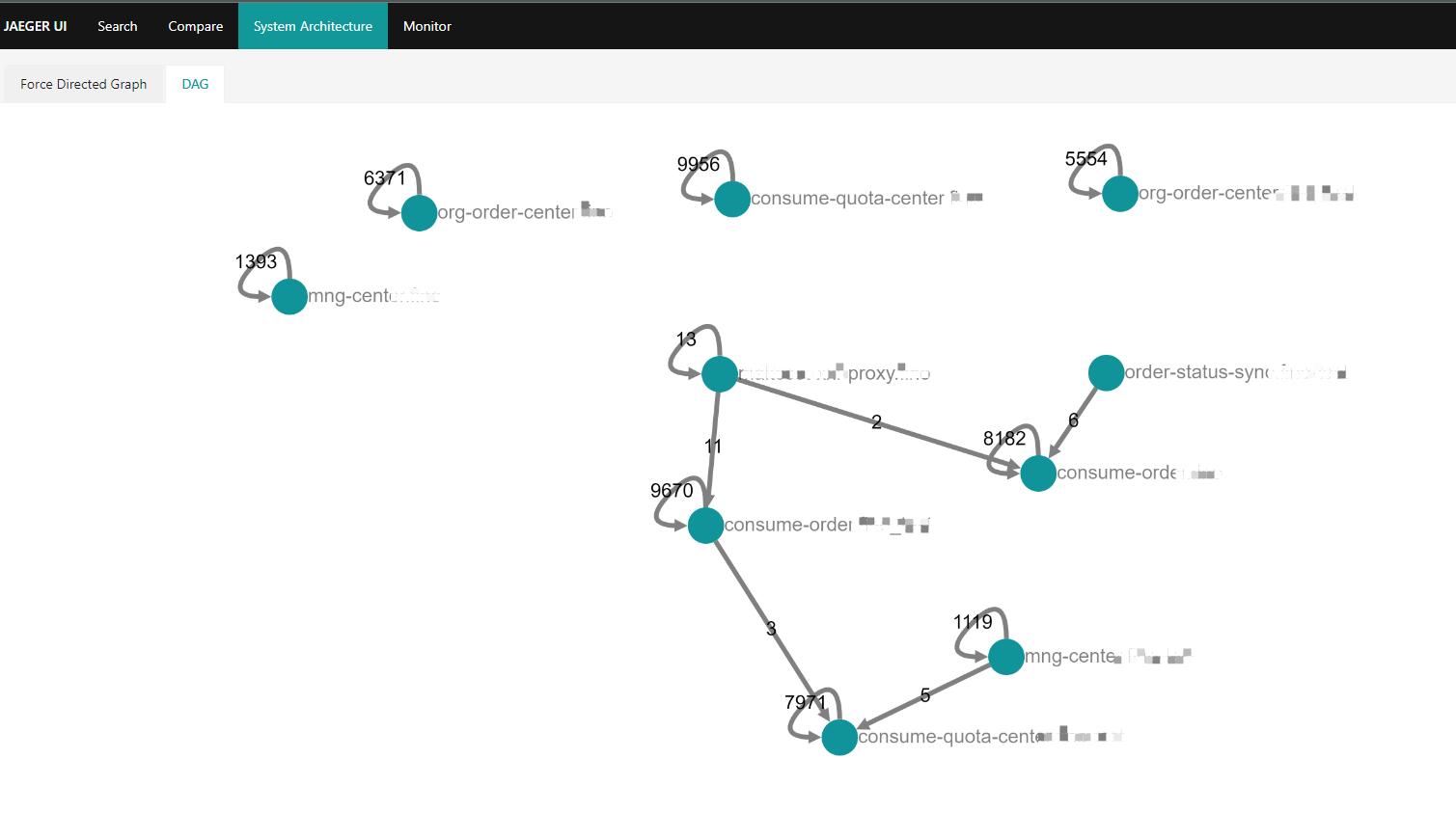 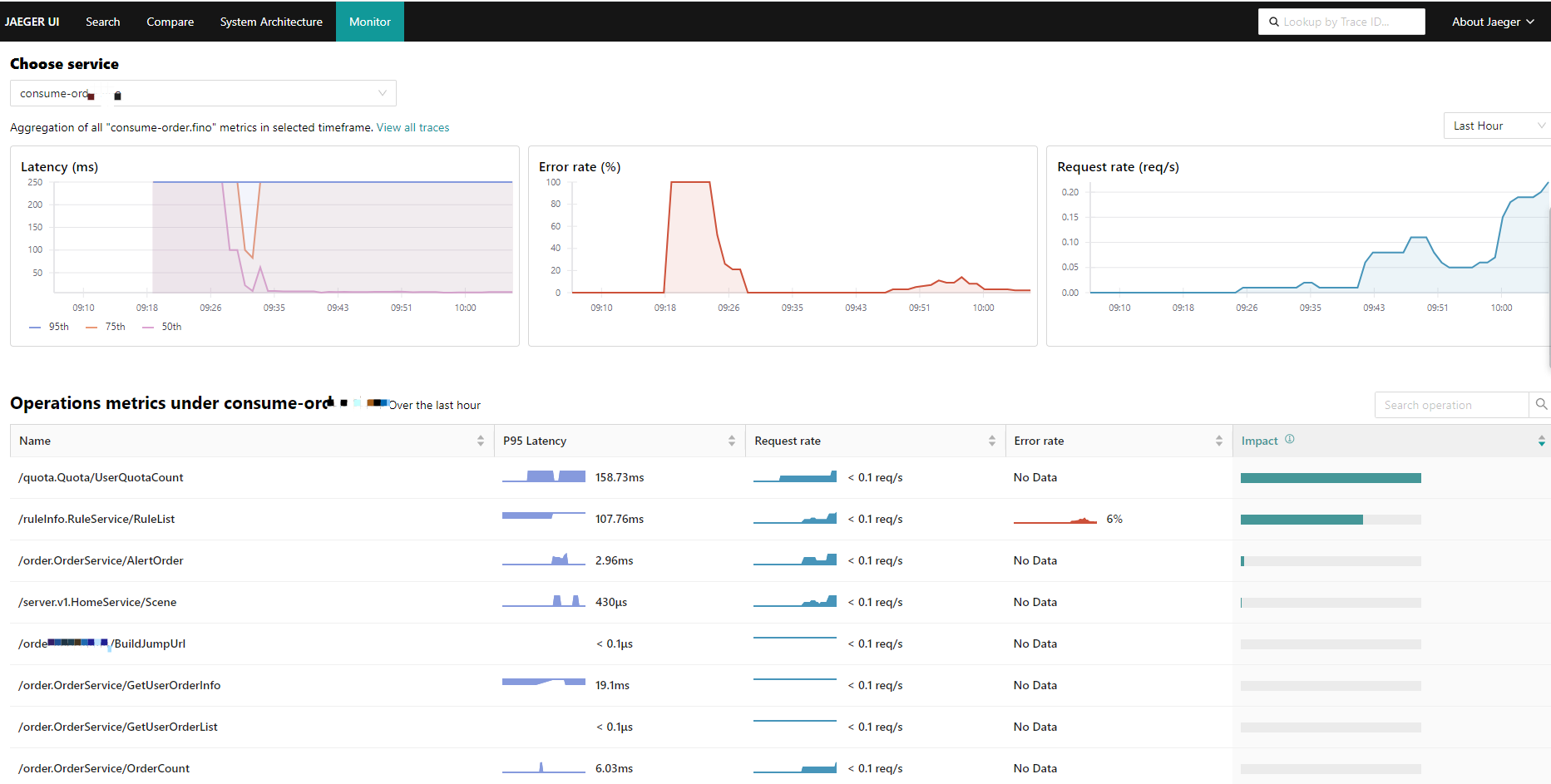 # 参考 https://www.jaegertracing.io https://opentelemetry.io https://prometheus.io https://aws.amazon.com/cn/what-is/jaeger/
上一篇:
opentelemetry-collector概述与helm安装
下一篇:
DockerInstall.sh
0
赞
302 人读过
新浪微博
微信
更多分享
腾讯微博
QQ空间
人人网
文档导航
