Toggle navigation
主页
English
K8S
Golang
Guitar
About Me
归档
标签
Welcome to Sanger's Blog!
Elasticsearch概述
无
2023-04-04 16:56:54
30
0
0
sanger
[TOC] # Elasticsearch Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 [Apache Lucene™](https://lucene.apache.org/core/) 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库—无论是开源还是私有。 但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常 复杂。 Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。 然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容: 一个分布式的实时文档存储,每个字段 可以被索引与搜索 一个分布式实时分析搜索引擎 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据 ## Elasticsearch与关系数据的类比对应关系如下: ``` Elasticsearch => Indices => Types => Documents => Fields Relational DB => Databases => Tables => Rows => Columns ``` ## 整体概述图 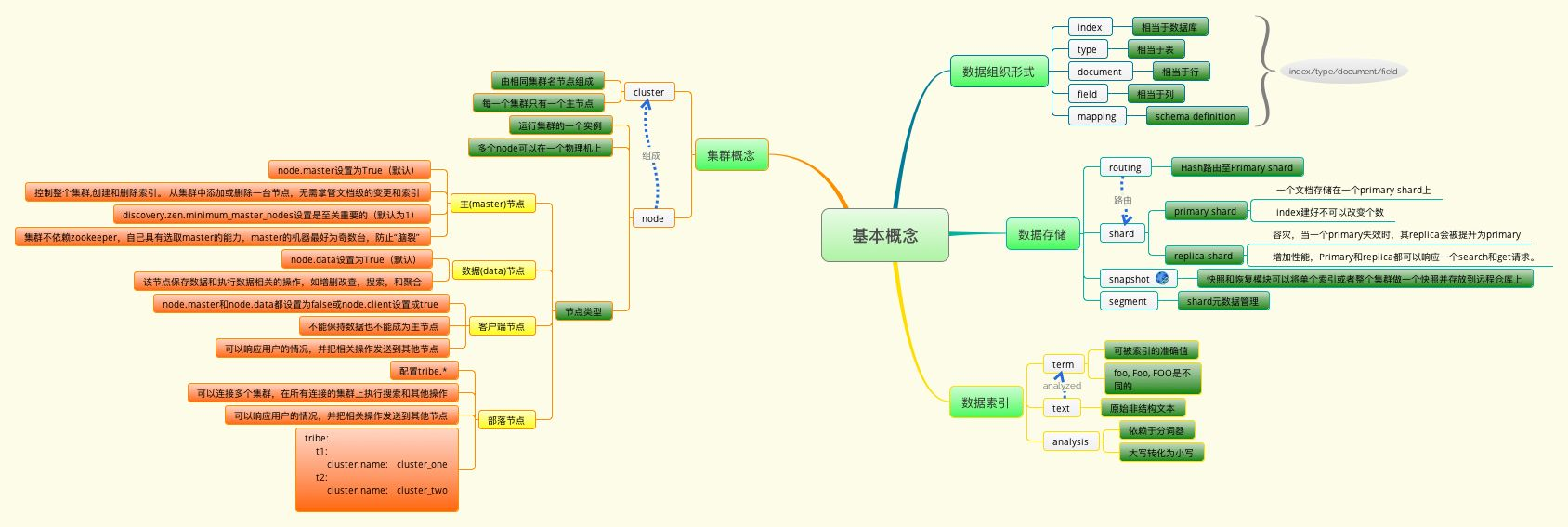 ## Cluster 集群,一个ES集群由一个或多个节点(Node)组成,每个集群都有一个cluster name作为标识。 ## node 节点,一个ES实例就是一个node,一个机器可以有多个实例,所以并不能说一台机器就是一个node,大多数情况下每个node运行在一个独立的环境或虚拟机上。 ### node.master ``` node.master: true #这个属性表示节点是否具有成为主节点的资格 ``` ### node.data ``` node.data: false #这个属性表示节点是否存储数据。 ``` ### 建议 - 主节点配置(CPU和内存消耗一般不大) ``` #建议集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态。 node.master: true node.data: false ``` - 数据节点配置(cpu消耗一般不大,内存和磁盘消耗较大) ``` # 再根据数据量设置一批data节点,这些节点只负责存储数据。 # 后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大所以在集群中建议再设置一批client节点。这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。 node.master: false node.data: true ``` ## index 索引,即一系列documents的集合。 ## type ## documents ## mapping ## segments ## shard 1. 每个索引有一个或多个分片,索引的数据被分配到各个分片上,相当于一桶水用了N个杯子装。 2. 分片有助于横向扩展,N个分片会被尽可能平均地(**rebalance**)分配在不同的节点上,例如你有2个节点,4个主分片(不考虑备份),那么每个节点会分到2个分片,后来你增加了2个节点,那么你这4个节点上都会有1个分片,这个过程叫 **relocation**,ES感知后自动完成。 3. 分片是独立的,对于一个Search Request的行为,每个分片都会执行这个Request。 4. 每个分片都是一个Lucene Index,所以一个分片只能存放 Integer.MAX_VALUE - 128 = 2,147,483,519 个docs。 ## replica 1. 复制,可以理解为副本分片,相应的有主分片(**primary shard**) 2. 主分片和副本分片不会出现在同一个节点上,这是为了防止单点故障,默认情况下一个索引创建5个分片,一个副本分片(即5p+5r=10) 3. 如果你只有一个节点,那么5个**replica**都无法分配(**unassigned**),此时**cluster status** 会变成`Yellow`。 4. 对于一个索引,除非重建索引否则不能调整分片的数目(主分片数, number_of_shards),但可以随时调整 **replica**(number_of_replicas) 5. **replica** 的作用主要包括: - 容灾: **primary** 分片丢失,**replica** 分片就会被顶上去成为新的主分片,同时根据这个新的主分片创建新的 **replica**,集群数据安然无恙 - 提高查询性能: **replica** 和 **primary** 的数据是相同的,所以对于一个query既可以查主分片也可以查备 ,在合适的范围内多个 **replica** 会更优(但要考虑资源占用也会提升[cpu/disk/heap]),另外 index request** 只能发生在主分片上,**replica** 不能执行 index request**。 ## 集群状态 ES集群状态有三种 ### Green 所有主分片和备份分片都准备就绪(分配成功),即使有一台机器挂了(假设一台机器一个实例),数据都不会丢失,但会变成Yellow状态 ### Yellow 所有主分片准备就绪,但存在至少一个主分片(假设是A)对应的备份分片没有就绪,此时集群属于警告状态,意味着集群高可用和容灾能力下降,如果刚好A所在的机器挂了,并且你只设置了一个备份(已处于未就绪状态),那么A的数据就会丢失(查询结果不完整),此时集群进入Red状态 ### Red 至少有一个主分片没有就绪(直接原因是找不到对应的备份分片成为新的主分片),此时查询的结果会出现数据丢失(不完整) # 参考 https://www.elastic.co/guide/cn/elasticsearch/guide/current/intro.html https://github.com/elastic/elasticsearch https://www.zhihu.com/question/26446020/answer/42049774 https://doc.yonyoucloud.com/doc/mastering-elasticsearch/chapter-1/121_README.html https://blog.csdn.net/crazymakercircle/article/details/120890619
上一篇:
Elasticsearch常用命令
下一篇:
Markdown 语法
0
赞
30 人读过
新浪微博
微信
更多分享
腾讯微博
QQ空间
人人网
文档导航
